
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- GCP
- Hadoop
- lazypredict
- Kaggle_Transcripition
- regression
- Data_Engineering
- Soft_skills
- kaggle
- fastcampus
- Algorithm_A/B_Test
- e-commerce
- 경제신문스크랩
- Kaggle #EDA #Regression
- SPARK
- Today
- Total
AI & Data를 활용하는 기술경영자
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction 본문
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
Data_Lover 2022. 7. 18. 12:33Intro

DeepFM: A Factorization-Machine based Neural Network for CTR Prediction을 분석하고 정리하였습니다. 그리고 추가적으로, 영화 데이터셋을 활용하여 실습부분도 함께 있습니다.
Abstract

- Click Through Rate(CTR)을 예측하는 모델이다.
- Low와 High-order feature interactions 모두 학습 가능하다.
- 저차원과 고차원의 특성을 공유하면서 End to End로 학습이다.
- 저차원과 고차원의 개별 특성값의 효과를 고려한 후 특성값을 변경함으로써 발생하는 예측값의 변화를 나타낸다.
- Factorization Machine의 장점과 Deep Learning의 장점을 모두 합친 모델인 DeepFM이다.
- Wide & Deep Model과 달리 추가 feature engineering없이 raw feature를 그대로 사용한다.
- Bench-mark data and commercial data를 활용하여 실험도 완료한다.
Introduction
- CTR: user가 추천된 항목을 click할 확률을 예측하는 문제이다.
- CTR(estimated probability)에 의해 user가 선호할 item랭킹을 부여한다.
- Learn Implicit Feature Interaction
- App category 와 Timestamp관계: 음식 배달 어플은 식사시간 근처에 다운로드가 많다.
- User gender와 Age관계: 남자 청소년들은 슈팅과 RPG게임을 선호한다.
- 숨겨진 관계: 맥주와 기저귀를 함께 구매하는 사람들이 많다.
- low와 high-order feature intreaction을 모두 고려해야 한다.
- Explicit와 Implicit features를 모두 모델링할 수 있다.
- 현재까지 추천알고리즘 연구 정리
- Generalized Linear Model(ex.FTRL)[McMahan et al.,2013]
- 당시 성능은 좋은 모델이었지만, High-order feature interaction을 반영하기 어렵다.
- Factorization Machine[Rendle,2010]
- Latent Vector간의 내적을 통해서 pairwise feature interaction 모델링한다.
- Low와 high-order 모두 모델링이 가능하지만, high-order의 경우 complexity가 증가한다.
- CNN and RNN for CTR Prediction[Liu et al.,2015;Zhang et al.,2014]
- CNN-based는 주변 feature에 집중하지만, RNN-based는 sequential해서 더 적합하다.
- Factorization-machine supported Neural Network(FNN), Product-based Neural Network[Qu et al.,2016; Cheng et al.,2016]
- Neural Network기반으로 high-order 가능하지만 low-order는 부족하다.
- Pre-trained FM 성능에 의존할 수 있다.
- Wide&Deep[Cheng et al.,2016]
- Low와 high-order 모두 가능하지만. wide component에 feature engineering이 필요하다.
- Generalized Linear Model(ex.FTRL)[McMahan et al.,2013]
Contributions

- DeepFM 모델 구조를 제안한다.
- Low-order는 FM, High-order는 DNN으로 구성된다.
- End-to-end 학습 가능하다.
- DeepFM은 다른 비슷한 모델보다 더 효율적으로 학습한다.
- Input과 embedding vector를 share 한다.(input, embedding layer 공유)
- DeepFM은 benchmark와 commercial 데이터의 CTR prediction에서 의미있는 성능향상을 이룸
DeepFM

Sparse features의 노란색 부분은 embedding vector(xfieldi * wi = Vi)에 해당된다.
- i : feature
- wi : scalar is used to weigh its order-1 importance
- Vi: latent vector is used to measure its impact of interactions with other feaures.
- Vi: is fed inFM component to model order 2-feature interactions, and fed in deep component to model high-order feature interactions.
간단한 수식


Prediction output
- All parameters
- wi, Vi and network parameters(W^(l), b^(l) ) are trained jointly for the combined prediction model
FM Component
Embedding vector의 내적을 order-2의 가중치로 사용

Figure 1 설명
- Normal Connection in black refers to a connection with weight to be learned
- Weight-1 Connection(red arrow) is a connection with weight 1 by default
- Embedding(blue dashed arrow) means a latent vector to be learned
- Addition means adding all input together
- Product including Inner and Outer Produt means the output of this unit is the product of two input vector.
- Sigmoid Function is used as the output function in CTR prediction
- Activation Functions, such as relu and tanh, are used for non-linearly transforming the signal.
- Yellow and blue circles in the sparse features layer represent one and zero in one-hot encoding of t

The addition unit(<w,x>) reflects and the importance of order-1 features.
The InnerProduct units represent the impact of order-2 feature interactions.
Deep Component
모든 embedding vector을 모두 합친 것이 input된다.

수식 이해하기

- Output of the embedding layer
- ei is the embedding of i-th
- m is the number of fields
- a^(0) is fed into the deep neural network

- The forward process of a^(0)
- a^(l) : output
- W^(l): model weight
- b^(l): bias of the l-th layer

- dense real-value feature vector
- |H| is the number of hidden layers
- FM component and deep component share the same feature embedding
- learns both low and high-order feature interactions from raw features
- no need for expertise feature engineering of the input
Relationship with the other Neural Networks

FNN
- It is FM-initialized feed-forward neural network
- The FM pre-training strategy results in two limitations
- The embedding parameters might be over affected by FM
- The efficiency is reduced by the overhead introduced by the pre-training stage
- It captures only high-order feature interactions but DeepFM needs no pre-training and learns both high-and low-order feature interactions.
PNN
- The purpose of capturing high-order feature interactions.
- It imposes a product layer between the embedding layer PNN imposes a product and the first hidden layer.
- Different types of product operation
- IPNN: it is based on inner product of vectors
- OPNN: it is based on outer product
- PNN* : it is based on both inner and outer products.
- It ignores low-order feature interactions.
Wide & Deep
- It is proposed by Google to model low and high-order feature interactions simultaneously.
- Need expertise feature engineering
- input: wide part
- Straightforward extension to this model is replacing LR by FM
- More precisely
Experiments
- Criteo Datase
- 45 million users'click records
- 13 continuous features, 26 categorical ones
- 90% for training and 10% for testing
- Company*Dataset
- 7 consecutive days of users'click records from Company*App Store
- Next 1 day for testing
- Approximately 1 billion records
- App features(identification, category)
- User features(user's downloaded apps)
- Context features(operation time)
- Evaluation Metrics
- AUC(Area Under ROC) and Logloss(Cross Entropy)
Effectiveness Comparison


- Linear model 대비 각 모델이 학습에 걸린 시간을 나타낸다
- FNN은 pre-training에 시간을 많이 쏟는다
- IPNN과 OPNN은 hidden layer에서 inner product를 하면서 시간이 매우 오래 걸린다.
Hyper-Parameter Study
Activation Function

- relu and tanh are more suitable for deep models than sigmoid
- In paper, Comparing the performance of deep models when applying relu and tanh.
- relu is more appropriate than tanh for all the deep models, except for IPNN.
- relu induces sparsity
Dropout
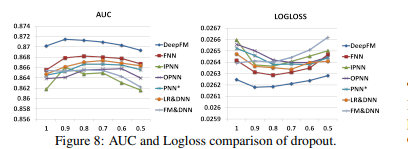
- The dropout is properly set(from 0.6 to 0.9)/
- Adding reasonable randomness to model can strengthen model's robustness
Number of Neurons per Layer

- 400 to 800 layers make overfitting
- 200 or 400 layers are a good choice
Number of Hidden Layers

- hidden layers의 수가 많아질수록 성능이 좋아진다.
- 그러나, 일정 수준을 넘으면 과적합이 일어난다.
Network Shape

- Different network shapes: Constant , Increasing , Decreasing, Diamond
- Fix: number of hidden layers and total number of neurons
Conclusions
- DeepFM
- deep component와 FM component를 합쳐서 학습한다.
- Pre-training이 필요하지 않다
- High와 low-order feature interactions둘 다 모델링한다.
- Input과 embedding vector를 share한다.
- From experiments
- CTRtask에서 더 좋은 성능을 얻을 수 있다.
- 다른 SOTA모델보다 AUC와 LogLoss에서 성능이 뛰어나다.
- DeepFM이 가장 efficient한 모델이다.
실습
dataset: kmrd
라이브러리: pytorch, torchfm
https://colab.research.google.com/drive/1faSTTlkqOXrmjTDMaWs8hteDNNdoUBXo?usp=sharing
DeepFM RS
Colaboratory notebook
colab.research.google.com
실습2
위의 코랩 실습이 부족하셨다면, 저의 깃허브를 들어와주세요!!
Pytorch, Tensorflow 그리고 movielens를 활용하여 실전 구현까지 담겨있습니다.!!
Rs-Paper/DeepFM at TIL · qsdcfd/Rs-Paper (github.com)
GitHub - qsdcfd/Rs-Paper
Contribute to qsdcfd/Rs-Paper development by creating an account on GitHub.
github.com
"모두의 연구소에서 진행하는 "함께 콘텐츠를 제작하는 콘텐츠 크리에이터 모임" COCRE(코크리) 2기 회원으로 제작한 글입니다. 코크리란? 🐘"COCRE 2기 회원으로서 작성한 글입니다. (로고) COCRE가 궁금하다면! 클릭!
COCRE(코크리)를 소개합니다!
코크리는 AI와 데이터 분석을 주제로 다양한 콘텐츠를 제작하는 오픈소스 콘텐츠 크리에이터 모임입니다.
medium.com
'Recommend_System' 카테고리의 다른 글
| 전통적인 추천시스템 알고리즘(2022/06/19~2022/07/16) (0) | 2022.06.26 |
|---|---|
| 추천 시스템 톺아보기(2022/06/05~2022/06/18) (0) | 2022.06.18 |

